国内无法访问raw.githubusercontent.com的原因基本是DNS污染,因此修改hosts可以解决该问题,例如使用IPAddress.com等网站查到真实IP后自行修改。同时,GitHub上也存在项目GitHub520对其进行实时更新(强烈推荐该项目)。
hosts的位置:
1 | # Windows |
国内无法访问raw.githubusercontent.com的原因基本是DNS污染,因此修改hosts可以解决该问题,例如使用IPAddress.com等网站查到真实IP后自行修改。同时,GitHub上也存在项目GitHub520对其进行实时更新(强烈推荐该项目)。
hosts的位置:
1 | # Windows |
采用disas phase_1生成对应汇编代码:
1 | 0x0000000000400ee0 <+0>: sub $0x8,%rsp |
<phase_1+9>处可以看出该句执行的是字符串比较,如果输入字符与0x402400处的不一致就发生爆炸。
使用print (char*)0x402400打印目标字符串,结果为Border relations with Canada have never been better.。
故phase_1的答案为:
1 | Border relations with Canada have never been better. |
采用disas phase_2生成对应汇编代码:
1 | 0x0000000000400efc <+0>: push %rbp |
<phase_2+9>处表明,该函数需要输入的是6个数值,<phase_2+48>处表明,该函数存在一个循环,循环节如下:
1 | 0x0000000000400f17 <+27>: mov -0x4(%rbx),%eax |
显然为一个数组结构,当a[i] + a[i] != a[i + 1]时被引爆。
同时,由<phase_2+14>处可以推出,a[0] = 1。
故phase_2的答案为:
1 | 1 2 4 8 16 32 |
采用disas phase_3生成对应汇编代码:
1 | 0x0000000000400f43 <+0>: sub $0x18,%rsp |
开始时解析输入字符串:
1 | 0x0000000000400f47 <+4>: lea 0xc(%rsp),%rcx |
print (char*)0x4025cf获得"%d %d",即输入两个整数。
由<phase_3+39>可知,输入的第一个数一定在被视为无符号整数时小于等于7。
在<phase_3+50>处可知,根据输入的第一个参数进行跳转表查询后进行跳转。使用x/8xg 0x402470获取跳转表:
1 | 0x402470: 0x0000000000400f7c 0x0000000000400fb9 |
跳转表中全部值均对应下述分支。
在<phase_3+127>处可知,第二个参数应该和第一个数跳转后的赋值相同。
故答案有多个,依次为(一行一个答案):
1 | 0 207 |
采用disas phase_4生成对应汇编代码:
1 | 0x000000000040100c <+0>: sub $0x18,%rsp |
如上文,0x4025cf处为"%d %d",即解析两个整数。
<phase_4+34>处表明,第一个参数应当小于等于15。
<phase_4+60>调用了函数func4。其中func4第一个参数与phase_4第一个参数相同,第二、三个参数分别为0和14。
<phase_4+65>处表明,func4的返回值应当为0。
<phase_4+65>处表明,执行func4后第二个参数应当为0。
使用disas func4对func4反编译:
1 | 0x0000000000400fce <+0>: sub $0x8,%rsp |
可以看出func4是一个递归程序,翻译成C语言代码如下:
1 | int func4(int edi, int esi, int edx) { |
于是问题变为使func4(x, 0, 14)为0的x值。
观察可得,只有当递归末端从1或3出口出,其他递归层均从3出口出时才为0。
同时,函数参数有如下变化:
1 | # 2出口进入时 |
因为输入的esi = 0,edx = 14,每次要求均从1或3出口出,所以有:
1 | 1: ecx = 7, 此时可以有edi = ecx <= 15,故可以直接另x = 15,直接返回。 |
故答案是:
1 | 7 0 |
采用disas phase_5获得对应汇编代码:
1 | 0x0000000000401062 <+0>: push %rbx |
由<phase_5+24>可知输入的是字符串,根据<phase_5+29>可知长度为6。
很显然,存在一个循环,循环节为:
1 | 0x000000000040108b <+41>: movzbl (%rbx,%rax,1),%ecx |
该循环将位于0x4024b0的字符串按照一定规则搬运到0x10(%rsp)处,其中每一个规则为映射后的字符串是0x4024b0的字符串取对应下标的输入字符串对应的整数的后4位的结果。
<phase_5+91>表明获得的字符串应当与位于0x40245e的字符串相同。
使用p (char*)0x4024b0打印0x4024b0字符串,取前16位的结果如下:
1 | 0x4024b0 <array> "maduiersnfotvbyl" |
使用p (char*)0x40245e打印0x40245e字符串,结果如下:
1 | 0x40245e "flyers" |
即输入的字符串对应的后4位的值应为:
1 | 0x9 0xf 0xe 0x5 0x6 0x7 |
为了便于输入,将其映射到a-o即可,故答案为:
1 | ionefg |
采用disas phase_6获得对应汇编代码:
1 | 0x00000000004010f4 <+0>: push %r14 |
<phase_6+18>表明,输入的是6个数值,解析后的数值放入栈中。
接下来进入一段循环中:
1 | 0x000000000040110b <+23>: mov %rsp,%r14 |
该循环依次遍历数组中的每个元素,并对其进行判断,要求每个元素两两均不相等且均在1-6之间。
接下来进入另一个循环:
1 | 0x0000000000401153 <+95>: lea 0x18(%rsp),%rsi |
该循环依次遍历数组中的每个元素,并使用7减去其之后的值替代原值。
接下来又进入新循环:
1 | 0x000000000040116f <+123>: mov $0x0,%esi |
其中存在一组小循环:
1 | 0x0000000000401176 <+130>: mov 0x8(%rdx),%rdx |
该循环显然处理的是一个链表结构,其从rdx处返回ecx位置的链表节点。
接下来进入另一个小循环:
1 | 0x0000000000401183 <+143>: mov $0x6032d0,%edx |
遍历7减操作后的数组,该循环用于根据处理后的取出对应链表节点指针并将其存放为数组,链表的头节点地址为0x6032d0。
故本段的作用是根据输入数组取出节点形成节点指针数组,指针节点数组的位置在0x20(%rsp)处。
接下来进行第三段大循环:
1 | 0x00000000004011ab <+183>: mov 0x20(%rsp),%rbx |
一开始是一段小循环:
1 | 0x00000000004011bd <+201>: mov (%rax),%rdx |
该段循环重建链表,使得其顺序与链表节点数组顺序相同。
1 | 0x00000000004011d2 <+222>: movq $0x0,0x8(%rdx) |
该段对重排后的链表节点进行判定,要求链表单调递减。
现在开始反推:
要求最终节点单调递减。
进行了链表重构,重构顺序为7减数组指定链表节点顺序。
故输入应该为1-6的组合,并且其7减数组使得单调递减。
令7减数组转为原数组即可。
x/1xw 0x6032d0得:
1 | 0x6032d0 <node1>: 0x0000014c |
x/2xg 0x6032d0得:
1 | 0x6032d0 <node1>: 0x000000010000014c 0x00000000006032e0 |
x/1xw 0x6032e0得:
1 | 0x6032e0 <node2>: 0x000000a8 |
x/2xg 0x6032e0得:
1 | 0x6032e0 <node2>: 0x00000002000000a8 0x00000000006032f0 |
x/1xw 0x6032f0得:
1 | 0x6032f0 <node3>: 0x0000039c |
x/2xg 0x6032f0得:
1 | 0x6032f0 <node3>: 0x000000030000039c 0x0000000000603300 |
x/1xw 0x603300得:
1 | 0x603300 <node4>: 0x000002b3 |
x/2xg 0x603300得:
1 | 0x603300 <node4>: 0x00000004000002b3 0x0000000000603310 |
x/1xw 0x603310得:
1 | 0x603310 <node5>: 0x000001dd |
x/2xg 0x603310得:
1 | 0x603310 <node5>: 0x00000005000001dd 0x0000000000603320 |
x/1xw 0x603320得:
1 | 0x603320 <node6>: 0x000001bb |
x/2xg 0x603320得:
1 | 0x603320 <node6>: 0x00000006000001bb 0x0000000000000000 |
希望值为单调递减的索引应为3 4 5 6 1 2。
故7减数组应当为:3 4 5 6 1 2。
故答案应为:
1 | 4 3 2 1 6 5 |
实际上还存在一个secret_phase,其入口在phase_defused中。
使用disas phase_defused获取phase_defused源码:
1 | 0x00000000004015c4 <+0>: sub $0x78,%rsp |
在<phase_defused+20>中,要求将0x202181(%rip)等于6,否则不会进入rip寄存器保存下一条指令地址,即最终目标为0x202181 + 0x4015df = 0x603760。x/1xw 0x603760得0,且其对应符号为num_input_strings。
在objdump -d bomb > bomb.s得到的bomb.s文件中查找num_input_strings,发现只在read_line中使用。
接下来,是对一段字符串的解析,0x603870为源字符串。p (char *)0x402619结果为%d %d %s。故应当解析出两个整数和一个字符串。
接下来进行字符串相等判断,p (char *)0x402622结果为"DrEvil"。因此第三个参数应该为DrEvil。
接下来打印两行字符串,p (char *)0x4024f8和p (char *)0x402520结果分别为"Curses, you've found the secret phase!"和"But finding it and solving it are quite different..."。
之后进入
使用disas read_line获取read_line源码:
1 | 0x000000000040149e <+0>: sub $0x8,%rsp |
在其中存在如下代码将num_input_strings的值增加1。
1 | 0x000000000040155e <+192>: mov 0x2021fc(%rip),%eax # 0x603760 <num_input_strings> |
接下来关注跳转语句,发现除了以下代码后,其他的跳转语句不能避开该上述指令。
1 | 0x000000000040153a <+156>: mov $0x0,%eax |
该句计算输入语句的长度,若为0时跳过递增指令。
经过上述分析,可明白num_input_strings代表使用read_line读入过的的非0字符串数。
接下来需要追踪0x603870处字符串由谁修改。显然该字符串是输入字符串(内部缓存会被复用,信息会被清除)。故是read_line的返回值。接下来查看read_line的返回值信息:
1 | 0x00000000004015bc <+286>: mov %rsi,%rax |
故查看rsi的最后修改处:
1 | 0x000000000040151f <+129>: mov 0x20223b(%rip),%edx # 0x603760 <num_input_strings> |
故返回值地址为0x603780 + 16 * 5 * num_input_strings,当其为0x603870时,解得num_input_strings为3,故应当在phase_4的答案结尾加上DrEvil,修改后的phase_4答案为:
1 | 7 0 DrEvil |
使用disas secret_phase获取secret_phase源码:
1 | 0x0000000000401242 <+0>: push %rbx |
<secret_phase+19>处表明输入的是一个数字,<secret_phase+30>表明该数字为正数且小于等于0x3e9。
<secret_phase+49>调用函数fun7,之后对返回值进行判断,要求其返回值为2。
之后打印一些信息后便结束了。
使用disas fun7获取fun7源码,其第一个参数为0x6030f0,第二个参数为输入参数:
1 | 0x0000000000401204 <+0>: sub $0x8,%rsp |
一个典型的二叉树递归,其对应的C代码应为:
1 | int fun7(TreeNode *root, long value) { |
接下来查看二叉树结点:
x/3xg 0x6030f0:
1 | 0x6030f0 <n1>: 0x0000000000000024 0x0000000000603110 |
x/3xg 0x603110:
1 | 0x603110 <n21>: 0x0000000000000008 0x0000000000603190 |
x/3xg 0x603130:
1 | 0x603130 <n22>: 0x0000000000000032 0x0000000000603170 |
x/3xg 0x603190:
1 | 0x603190 <n31>: 0x0000000000000006 0x00000000006031f0 |
x/3xg 0x603150:
1 | 0x603150 <n32>: 0x0000000000000016 0x0000000000603270 |
x/3xg 0x603170:
1 | 0x603170 <n33>: 0x000000000000002d 0x00000000006031d0 |
x/3xg 0x6031b0:
1 | 0x6031b0 <n34>: 0x000000000000006b 0x0000000000603210 |
x/3xg 0x6031f0:
1 | 0x6031f0 <n41>: 0x0000000000000001 0x0000000000000000 |
x/3xg 0x603250:
1 | 0x603250 <n42>: 0x0000000000000007 0x0000000000000000 |
x/3xg 0x603270:
1 | 0x603270 <n43>: 0x0000000000000014 0x0000000000000000 |
x/3xg 0x603230:
1 | 0x603230 <n44>: 0x0000000000000023 0x0000000000000000 |
x/3xg 0x6031d0:
1 | 0x6031d0 <n45>: 0x0000000000000028 0x0000000000000000 |
x/3xg 0x603290:
1 | 0x603290 <n46>: 0x000000000000002f 0x0000000000000000 |
x/3xg 0x603210:
1 | 0x603210 <n47>: 0x0000000000000063 0x0000000000000000 |
x/3xg 0x6032b0:
1 | 0x6032b0 <n48>: 0x00000000000003e9 0x0000000000000000 |
这是一棵4层的满二叉树,结点的层序遍历后结果值序列如下:
1 | 0x24 0x8 0x32 0x6 0x16 0x2d 0x6b 0x1 0x7 0x14 0x23 0x28 0x2f 0x63 0x3e9 |
此时有以下root移动方式使得结果为2:
less more
less more less
故结果值可能为0x16和0x14,均符合条件。
故答案为(一行一个):
1 | 22 |
最后附上通过的截图:
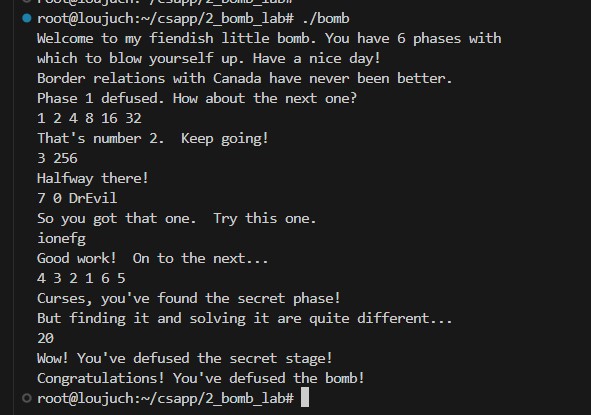
描述:仅使用~和&实现^操作。
允许使用的操作符:~ &
允许使用的操作符最大数量:14
1 | int bitXor(int x, int y) { |
有:
x ^ y = (x | y) & (~(x & y))
x | y = ~((~x) & (~y))
故:
x ^ y = (~((~x) & (~y))) & (~(x & y))
描述:返回二进制补码整数的最小值。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:4
1 | int tmin(void) { |
INT_MIN为0b10[31],故将1左移31位即可
描述:判断输入参数是否是二进制补码整数所能表示的最大值,是则返回1,否则返回0。
允许使用的操作符:! ~ & ^ | +
允许使用的操作符最大数量:10
1 | int isTmax(int x) { |
INT_MAX为0b01[31],可知~INT_MAX = INT_MAX + 1。下面证明除了INT_MAX和0b1[32]外无其他数使得~x = x + 1:
对于任何
a,除了0b1[32]外,均有a = A01[n]。此时~a = ~A10[n],a + 1 = A10[n],若希望~a = a + 1,要求A = ~A,这只有当A为空的情况下成立。同时,
~0b1[32] = 0b0[32],0b1[32] + 1 = 0b0[32],同样成立。
因此,本题实质上进行如下判断:
x + 1 == ~x,当(x + 1) ^ ~x为零时成立
x != 0b0[32],当~x不为零时成立。
描述:判断输入参数的所有奇数位上的数值是否为1,下标从0开始。是则返回1,否则返回0。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:12
1 | int allOddBits(int x) { |
其实本题最简单的思路是构造mask = 0xAAAAAAAA,判断x & mask是否等于mask即可。
目前采用的思路是遍历。利用&操作符的x & (y & z) = x & y & z的性质逐层计算,最终获得结果。原理示意图如下图:
描述:返回输入参数的相反数。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:5
1 | int negate(int x) { |
x + (-x) = 0b0[32] = 0b1[32] + 0b1
所以有:
(-x) = 0b1[32] + 0b1 - x = (~x) + 0b1
描述:返回输入参数的值是否在[0x30, 0x39]区间内,是则返回1,否则返回0。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:15
1 | int isAsciiDigit(int x) { |
经分析,有如下条件:
x <= 0x3f,故有x & (~0x3f)为0
x >= 0x30,故有(x & 0x30) ^ 0x30为0
x <= 0x39,根据其对应二进制特征,可分为以下两类:
0x30 <= x <= 0x37,其特征为后4个比特为0b0xxx,故有x & 0x8为0
0x38 <= x <= 0x39,其特征为后4个比特为0b100x,故有(x & 0xe) ^ 0x8为0
上述两项只要有一项为0即可,故采用&进行连接。为了保证二者均不为0时结果也不为0,使用!!对剩下的位数进行对齐。
描述:要求函数行为与x ? y : z一致。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:16
1 | int conditional(int x, int y, int z) { |
做出如下mask,当x = 0时,mask = 0b1[32];当x != 0时,mask = 0b0[32]。之后对输入进行&操作即可。
描述:判断是否有x <= y,是则返回1,否则返回0。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:24
1 | int isLessOrEqual(int x, int y) { |
进行如下判断:(-x) + y >= 0。又有(-x) = ~x + 0b1。故进行计算后判断符号位即可。
描述:行为应与!x相同。
允许使用的操作符:~ & ^ | + << >>
允许使用的操作符最大数量:12
1 | int logicalNeg(int x) { |
制作如下mask:x = 0时,mask = 0b0[32],x != 0时,mask = 0b1[32]。最后按位取反并取最后一位即可。
描述:返回表示x需要的最少位数。
允许使用的操作符:! ~ & ^ | + << >>
允许使用的操作符最大数量:90
1 | int howManyBits(int x) { |
本次实验中最难的题,根据题意,其实际上是在找去除多余符号位后的整数补码表示位数。
首先,为了简化情况,观察到howManyBits(x) = howManyBits(~x),于是选择将负数取反。这一步中涉及一些位运算技巧:
1. 对0的`^`相当于取反,对1的`^`则保持原值。
2. `int`的右移为算数右移,右移31位的结果相当于获得一个由符号位填充的`mask`。
之后,为了便于计算,将x转化为0b0[n]1[32-n]的形式(之前的负数要取反也是为了统一该步的操作)。
接下来,使用mask和移位操作,统计x中1的个数,其过程示意图如下图:
将得到的x加上一位符号位获得最终结果。
描述:返回2 * x的二进制表示,对于INF和NaN原样返回。
允许使用的操作符:任意int/unsigned的算数运算符、||、&&运算符和if、while关键字。
允许使用的操作符最大数量:30
1 | unsigned floatScale2(unsigned uf) { |
根据浮点数的结构,将其拆分成s、exp和frac。
对于NaN和INF,直接返回原数据。
对于非规格化数,将frac右移一位即可。注意,此时非规格化数可能会转化成规格化数,但转化后的结果为exp = 1和frac & ~0x800000,在组装成为浮点数后的结果与直接进行组装相同,故不需要进行特殊处理。
对于规格化数,需要将exp加1。但在操作后有可能导致溢出,故需要将frac置0,将结果设为INF而不是NaN。
描述:返回(int)x的返回值,对于INF和NaN和溢出值返回0x80000000。
允许使用的操作符:任意int/unsigned的算数运算符、||、&&运算符和if、while关键字。
允许使用的操作符最大数量:30
1 | int floatFloat2Int(unsigned uf) { |
根据浮点数的结构,将其拆分成s、exp和frac。
对于INF和NaN,直接返回0x80000000。
对于非规格化数,直接返回0。
对于规格化数,需要现根据exp判断其是否溢出或为0。注意,由于我们将目前的计算视为正数,故原则上需要特别INT_MIN,但应为本次溢出返回值即为INT_MIN,因此可以两者进行合并处理,只要发生正数溢出便返回INT_MIN。
根据符号位将其转化成为补码。
代码中各个数值的出现的原因:
0x7f:即加上偏置值后
exp实际为0时的exp值。若exp小于该值,则该浮点数不存在整数部分。0x96:因为在取
frac的时候是整数形式,因此实际上暗中给其加上了一层偏置,大小为frac小数部分位数23。故有0x7f + 0x17 = 0x96。若exp小于该值,则frac需要右移,否则需要左移。0x9e:对于规格化整数,在其
frac中的整数部分的1到达符号位时发生溢出,此时右移位数为31。固有0x7f + 0x1f = 0x9e。若exp小于该值,则规格化数不会溢出,否则发生溢出。
描述:返回2.0 ^ x的二进制表示,如果结果过大则返回+INF
允许使用的操作符:任意int/unsigned的算数运算符、||、&&运算符和if、while关键字。
允许使用的操作符最大数量:30
1 | unsigned floatPower2(int x) { |
当x大于等于128时,超过浮点数最大值,发生溢出,返回+INF。
当x大于-127小于128时,是规格化数,只需要处理exp部分。
当x小于-150时(-150 = -127 + -23),超出浮点数精度,返回0。
否则,为非规格化数,只需要处理frac部分。
1 |
|
效果如下图:
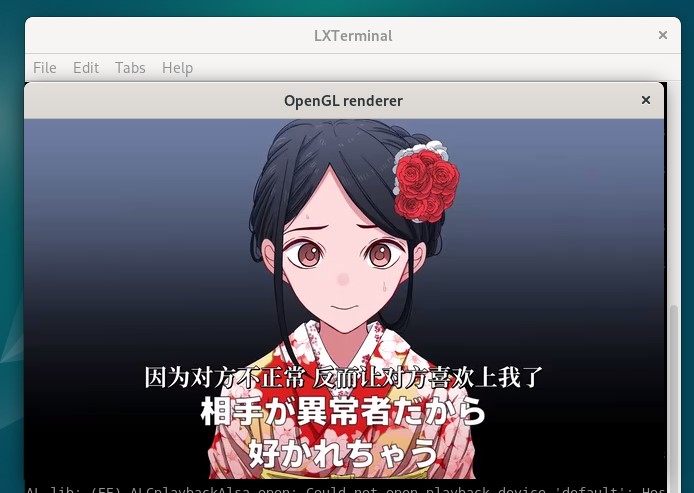
1 | gst_init(&argc, &argv); |
gst_init用于初始化,必须在其他GStreamer接口之前被调用,不需要其处理命令行参数时可将参数赋值为NULL。
1 | GstElement *pipeline = gst_parse_launch("playbin uri=file:///root/video.mp4", NULL); |
创建了一个Pipeline,该Pipeline是Playbin类型的。
GStreamer是一个基于管道机制的多媒体库,一个典型的GStreamer程序包含了一个或多个Pipeline,每个Pipeline通过其拥有的一系列Element完成对多媒体数据的处理。同时,虽然是由C语言实现的,但GStreamer实现了自己的面向对象机制,因此其各类型间具有继承关系。
本句中涉及了两个类型,GstPipeline和playbin。
其中,GstPipeline是一个在GStreamer当中十分重要的类型,其继承关系如下所示。
1 | GObject |
GstElement是一个抽象基类,定义了Element、Pipeline等的接口,在GStreamer中该接类被广泛的用作基类。
GstBin是一个能够容纳和管理其他GstElement的类型,其能够将用户的操作分发到其管理的多个GstElement中,降低了使用复杂性。同时,GstBin还提供了对GstMessage的拦截功能。
GstPipeline通常被用作顶层的容器,其进一步的拓展了GstBin的功能,对内提供了用于多媒体数据同步的全局时钟GstClock,对外提供了统一的消息接口GstBus。
而playbin则是扩展了GstPipeline的功能,其能够通过有效的Uri获取数据并将其渲染到屏幕上。因为其功能的完整性和高度的集成化,本文不对其进行展开叙述。
gst_parse_launch则通过解析传入字符串来创建指定的GstPipeline。
1 | gst_element_set_state(pipeline, GST_STATE_PLAYING); |
gst_element_set_state用于设置GstElement的状态,该句将pipeline设为了播放状态,使得视频开始能够播放。
正如上文所说的,GstBin能对其管理的GstElement进行统一操作。实际上在该句之后pipeline中包含的所有GstElement都转变为了播放状态,这才使得多媒体数据顺利播放。
每一个GstElement都具有内部状态,通常使用的是以下几个:
1. GST_STATE_NULL:默认状态,该状态下[GstElement](https://gstreamer.freedesktop.org/documentation/gstreamer/gstelement.html?gi-language=c)不会具有任何资源。转入该状态后会释放持有的资源。
2. GST_STATE_READY:在该状态下[GstElement](https://gstreamer.freedesktop.org/documentation/gstreamer/gstelement.html?gi-language=c)将获得全部需要的资源,包括打开的设备、缓冲区等,但流还是会处于关闭状态并被置零。如果在流打开过的情况下转入该状态,将会重置流的配置和位置。
3. GST_STATE_PAUSED:在该状态下[GstElement](https://gstreamer.freedesktop.org/documentation/gstreamer/gstelement.html?gi-language=c)不仅具有GST_STATE_READY分配的全部资源,还会将流打开,使得能够对流进修改。但不会具有运行时钟,流不会随着时钟而发生变化。
4. GST_STATE_PLAYING:在该状态下[GstElement](https://gstreamer.freedesktop.org/documentation/gstreamer/gstelement.html?gi-language=c)的情况与GST_STATE_PAUSED基本相同。但是会具有运行时钟,流会自然地随时钟信号进行处理。
1 | GstBus *bus = gst_element_get_bus(pipeline); |
这两句分别用于获取消息总线和等待播放程序运行完毕。
gst_element_get_bus返回传入的GstElement对应的GstBus。
GstBus是一个能够传递GstMessage的类型。GstBus主要用于解决多线程通信的问题。在播放时,GStreamer内部可能会创建多个线程进行处理,这使得GStreamer需要一个统一的消息传递机制来降低应用程序的复杂度。
gst_bus_timed_pop_filtered则用于监听传入的GstBus,等待目标消息的返回。根据该句的传入参数,程序将会无限等待,直到有发生错误或播放完毕的消息传回。
GstMessage是GStreamer封装的消息类型。一个常用的读取程序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
if(msg != NULL) {
GError *err;
gchar *debug_info;
switch (GST_MESSAGE_TYPE (msg)) {
case GST_MESSAGE_ERROR:
gst_message_parse_error (msg, &err, &debug_info);
g_printerr ("Error received from element %s: %s\n",
GST_OBJECT_NAME (msg->src), err->message);
g_printerr ("Debugging information: %s\n",
debug_info ? debug_info : "none");
g_clear_error (&err);
g_free (debug_info);
break;
case GST_MESSAGE_EOS:
g_print ("End-Of-Stream reached.\n");
break;
default:
/* We should not reach here because we only asked for ERRORs and EOS */
g_printerr ("Unexpected message received.\n");
break;
}
gst_message_unref (msg);
}
1 | if(msg != NULL) |
本段进行了资源释放。由于C语言没有析构函数和垃圾回收等资源管理机制,因此仍然需要进行手动管理。
GStreamer使用引用计数的方式来管理资源。通过在每个类型中放置一个引用数,并在引用数归零是才进行资源释放的方式,能够避免资源的过早释放,因此在使用GStreamer提供的API时,需要着重关注其对引用计数的影响。
gst_object_unref能够将输入的变量的引用计数减一,归零时自动释放。
与之对应的gst_object_ref能够将输入的变量的引用计数加一。
GStreamer使用以下命令进行安装GStreamer:
1 | sudo apt-get install libgstreamer* gstreamer1.0-* -y |
使用如下命令查看GStreamer的编译命令。
1 | pkg-config --cflags gstreamer-1.0 # 获得头文件路径 |
使用如下demo.c进行测试:
1 |
|
使用如下命令进行编译:
1 | gcc demo.c -o demo `pkg-config --cflags --libs gstreamer-1.0` |
使用如下命令运行:
1 | ./demo |
出现一个窗口播放视频,证明安装成功:
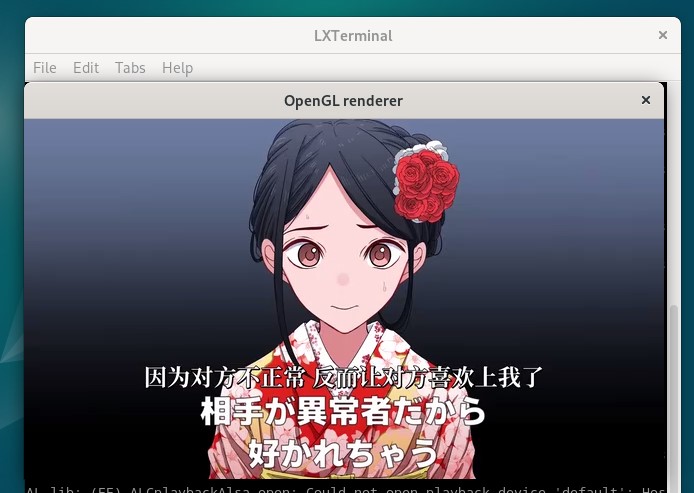
由于之前的开发环境中未安装桌面环境,为了能够看到GStreamer程序执行结果,因此需要安装新的桌面环境。
使用下列命令最小化安装gnome,并设置startx启动:
1 | sudo apt install xorg gnome-core |
之后可以看到启动后的gnome桌面。
为了提高开机速度和降低性能损耗,希望开机默认进入命令行,只在需要时进入桌面环境。
修改/etc/default/grub文件,将GRUB_CMDLINE_LINUX的值从""改为"text"。
之后执行以下命令:
1 | sudo update-grub |
重启后会发现直接进入命令行。
post_asset_folder当post_asset_folder为true时,hexo new <title>指令会在对应的文件生成路径下生成一个同名文件夹。可以使用asset_*类的选项该文件夹内的资源,如加载图片是可以使用{% asset_img image.jpg %}进行加载。
在hexo-renderer-marked 3.1.0后提供了新选项,可以使用的方式加载图片,具体打开形式如下:
1 | post_asset_folder: true |
permalink表示文章的永久链接格式,通俗来说就是访问该文章是域名后面的部分。通常将其设置为:
1 | permalink: :year/:month/:day/:name/ |
new_post_name创建新文章的路径名。通常将其设置为:
1 | new_post_name: :year/:month/:day/:title.md |
这样可以使得不同日期写的文章放置在不同的文件夹下,便于管理。
现存如下GStreamer管道:
1 | typedef struct g_pipeline0_style { |
两个管道间使用如下函数进行链接:
1 | GstFlowReturn on_new_sample(GstAppSink *sink, gpointer user_data) { |
但在运行时报错:
1 | GStreamer-Wayland:ERROR:../gst-plugins-bad-1.22.0/gst-libs/gst/wayland/gstwlbuffer.c:178:gstmemory_disposed: assertion failed: (!priv->used_by_compositor) |
查看日志,发现第一条错误如下:
1 | ERROR waylandsink gstwaylandsink.c:1181:gst_wayland_sink_show_frame:<waylandsink> buffer buffer: 0x55a234bbf0, pts 0:00:00.000000000, dts 0:00:00.000000000, dur 0:00:00.033333333, size 3072000, offset none, offset_end none, flags 0x40 cannot have a wl_buffer |
主要是因为缓冲区类型和数据类型不匹配导致的。WaylandSink仅支持DMA Buffer携带的RGB数据,但在复制后,Buffer类型变成了Share Memory Buffer,这是WaylandSink不支持的,因此报错。
虽然从理论上来说将复制出的Buffer转换为DMA Buffer就可以解决该问题。但笔者工作较忙没有进行论证。
还有一种妥协性的解决方法,就是去除pipeline0->v4l2convert和pipeline0->rgb_filter,将pipeline1->rgb_filter类型转换为YUY2,这样到达WaylandSink的就是YUY2,而WaylandSink支持携带YUY2数据的Share Memory Buffer。
因为要配置使用https的源,这需要先确保安装证书认证工具:
1 | sudo apt install ca-certificates -y |
编辑系统文件/etc/apt/sources.list,其中阿里云源如下:
1 | deb https://mirrors.aliyun.com/debian/ bookworm main non-free non-free-firmware contrib |
使用sudo apt update更新源。